
By Bruno Machado Carneiro, Michele Linardi, Julien Longhi
(This paper has been accepted for publication in the International Conference on CMC and Social Media Corpora for the Humanities – 2023)
In this article, we review the main aspects of our study about state-of-the-art Artificial Intelligence (AI) technology applied to automatic Socially Unacceptable Discourse (SUD) detection. The first author of our research outcome is Bruno Machado Carneiro (master’s student of ENSEA – graduate school of Electrical Engineering and Computer Science in Cergy – France). Michele Linardi (Assistant Professor of Cergy-Paris Université – France) and Julien Longhi (Professor at the Cergy-Paris Université) supervised this work in the context of Working Package (WP) 2 of the ARENAS project.
The objective of such WP is to design AI models that aid the detection and characterisation of Extremist Narratives in Social Media corpora. Julien is also the leader of ARENAS, for which he is responsible for coordination and project management.
Socially unacceptable discourse (SUD) is an umbrella term adopted to represent any communication considered harmful or inappropriate in a particular social context. It can include a variety of behaviours, such as abusive, obscene, and aggressive language. In this last decade, we have witnessed a tremendous effort from the Machine Learning (ML) and Computational Linguistic (CL) community to propose automatic SUD detection techniques in annotated online corpora.
We note that, in all the available corpus, no standard or common guidelines for SUD annotation exist despite the adoption of the same terminology and tags. It derives that different SUD definitions may potentially share overlapping characteristics, or on the other hand, a single category may cover text instances with divergent features depending on the context.
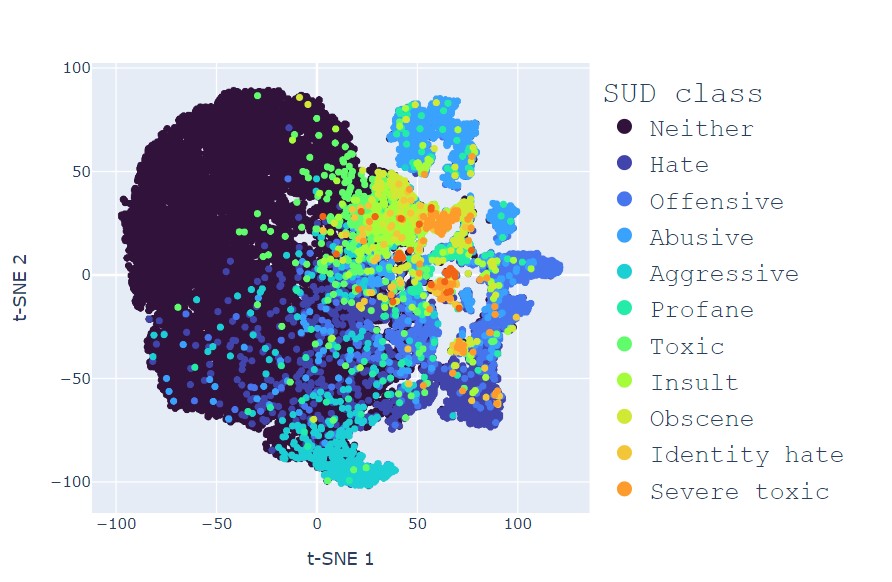
In our paper, we first build and present a novel corpus that contains a large variety of manually annotated texts from different online sources used so far in state-of-the-art ML SUD detection solutions. This global context allows us to test the generalisation ability of state-of-the-art SUD classifiers based on the BERT Artificial Intelligence (AI) model proposed by Google.
In the proposed environment, the solutions we test acquire knowledge around the same SUD categories from different contexts. In this manner, we can analyse how (possibly) diverse annotation modalities influence SUD learning.
Specifically, our goal is to stress-test the capability of cutting-edge SUD detection technology in facing two critical challenges: (1) adapting to different domains that follow shared linguistic definitions and (2) how to transfer knowledge from one domain to another.
This exercise has permitted us to discuss several aspects that concern the current capability of AI technology to identify SUD texts, highlighting several limitations. Following our empirical results, we are firmly convinced that to build more general and reliable models, the ML community should consider formal guidelines provided by language experts (mostly neglected so far), which can sensibly reduce local bias (e.g., annotation policy, context, etc.). Our results have also highlighted inter-domain mismatches that negatively affect the model detection performance.
Such findings enable us to carve out our research directions, which concern the improvement of textual feature learning and will permit us to define effective communication with expert and non-expert annotators (about requirements and expectations).
We furthermore note that the results and the insights we obtained also have the potential for the research linguists, discourse analysis, or semantics, as they show, from a knowledge base constituted by the main works on SUD corpora, the semantic links, and conceptual relationships, between several labels or tags. In fact, over and above terminology, it is crucial to clearly state and understand the specific features of hate speech, offensive speech, or extremist speech.
These initial results are necessary to foster several research discussions in the ARENAS project. In fact, in WP 2 of ARENAS, understanding the various mechanisms behind the text modelling and annotation principles adopted in SUD detection literature represents a crucial step. First of all, to detect the similarities between SUD and Extreme Narrative textual features, and in the second stage, to define and address open research questions that concern the peculiarities of Extreme Narrative.
The paper is available in the CMC Corpora 2023 proceedings and on arXiv (https://arxiv.org/abs/2308.04180).
The interested reader can check the evolution of future research outcomes here: